
[텍스트 처리]
리눅스의 가장 기초이자 시작점이 되는 부분이 바로 텍스트 처리이다.
텍스트 처리를 위해서는 텍스트 파일이 있어야 하는데,
우리가 평소에 윈도우에서 사용하던 GUI 방식이 아닌, CLI 방식으로 처리해야 하기 때문에
기본적인 셋팅이 필요하다.
📌 wget (텍스트 파일 다운로드)
// 사용법
$ wget [URL]
// 예시
$ wget https://www.gutenberg.org/cache/epub/71885/pg71885.txt
✅ 리눅스에서 복사 & 붙여넣기
리눅스 환경에서는 우리가 윈도우에서 사용한 방법인, Ctrl + C, Ctrl + V를 사용하지 못한다.
터미널에서 Ctrl + C는 프로세스를 종료시키는 단축키이며,
터미널에서 복사 & 붙여넣기를 하는 방법은 다음과 같다.
복사 : Ctrl + Insert 또는 Ctrl + Shift + C
붙여넣기 : Shitf + Insert 또는 Ctrl + Shift + V
단, 마우스가 없는 서버 버전에서는 사용 불가
그래도 다행인 점은 Vim 같은 편집기에는 키보드를 활용해서 복붙하는 방법이 있다.
✅ 윈도우에서 wget 사용하기

지금 우리는 윈도우 운영체제에서 리눅스를 사용하고 있기 때문에 리눅스 명령어인 wget이 지원되지 않는다.
따라서 윈도우용 wget 실행 파일을 다운받아야 한다.
GNU Wget 1.21.4 for Windows
eternallybored.org
① 위에서 현재 사용 중인 운영체제에 맞는 버전을 다운받고
② Windows의 System32 폴더에 넣어주고
③ 전 가이드에서 했던 것처럼 환경변수에 wget.exe 파일의 경로를 추가해준다.
다시 본론으로 돌아와서,
만약에 URL을 잘못 입력하거나 더 이상 유효하지 않은 URL을 입력하면,
HTTP request sent, awaiting response... 404 Not Found 라는 메세지가 출력된다.
정상적으로 다운로드되었다면,
HTTP request sent, awaiting response... 200 OK 메세지가 출력된다.

cf) 요즘은 전자책들도 다 epub 형식으로 업로드되어
웹 상에서 링크로 txt를 다운받을 수 있는 곳을 찾기가 어렵다.
그래서 그냥 아무 사이트에서 제공하는 메뉴얼을 다운받았음.
📌 cat / tac
cat명령어의 경우, 기본 명령어 가이드에서 다뤄봤던 것이다.
파일의 내용을 출력하거나 결합하는 기능을 가지고 있는데, 우리는 내용을 출력하는 기능을 사용할 것이다.
// 사용법
$ cat [파일명][.확장자]
$ cat [파일명1][.확장자] [파일명2][.확장자] [파일명3][.확장자] // 여러 파일 한 번에 출력
// 예시
$ cat features.en.txt

결합 기능은 아래와 같다.
파일1과 파일2를 합쳐서 파일3를 만들어보자.
// cat을 이용한 파일 결합
$ cat [파일명1][.확장자] [파일명2][.확장자] > [파일명3][.확장자]
✅ IO Redirection(입출력 방향 변경)
리눅스에서 > 와 < 표시는 입출력의 방향 변경을 표시하는 기호이다.
> : 출력 방향 변경
< : 입력 방향 변경
위의 예시를 들어 설명해보면,
처음에는 $ cat [파일명1][.확장자] [파일명2][.확장자] [파일명3][.확장자]
두 번째는 $ cat [파일명1][.확장자] [파일명2][.확장자] > [파일명3][.확장자]
이렇게 작성했는데, 차이점은 >(출력 방향 변경) 의 유무이다.
기본적으로 출력은 CLI 콘솔 창이지만, 우리가 파일 두 개를 파일3로 출력하는 것으로 바꿨기에
파일1과 파일2가 파일3에 결합되어 저장된 것이다.
// 사용법
$ tac [파일명1][.확장자]
// 파일의 내용을 행 단위로 뒤집어서 출력한다.
$ tac features.en.txt
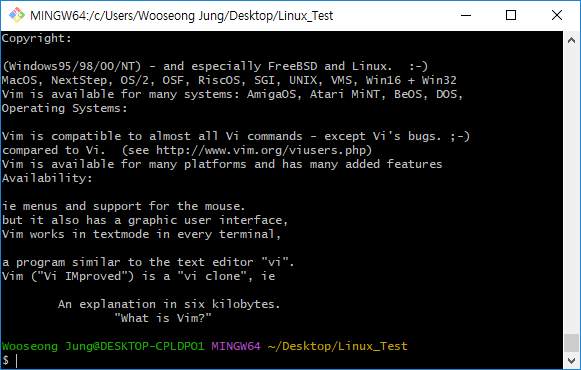
결과를 보면, 행 단위로 거꾸로 출력되는 것을 볼 수 있다.
📌 more / less
// 사용법
$ more [파일명][확장자]
$ less [파일명][확장자]
// 예시
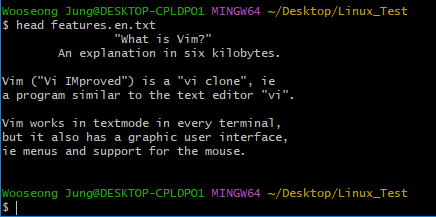
$ more features.en.txt
$ less features.en.txt
cat 명령어의 경우, 텍스트 전체 내용이 한 번에 다 출력되기 때문에 긴 글을 보기에 적합하지 않다.
장문의 텍스트를 한 화면씩 볼 수 있도록 해주는 명령어가 바로 more / less이며,
more는 뒤로 갈 수는 있지만 전으로는 돌아갈 수 없는 명령어이고
less는 앞 뒤로의 이동이 자유롭다(방향키 위/아래 활용)
또한 /[검색어] 기능을 활용하여 키워드를 검색해서 읽을 수도 있다
추가 기능)
- less 상태에서 h를 누르면, 도움말
- 도움말에서 나가려면 q
📌 head / tail
해당 명령어는 "처음부터~까지" 또는 "~부터 끝까지" 의 내용을 출력하는 명령어이다.
// 사용법
head [파일명][확장자]
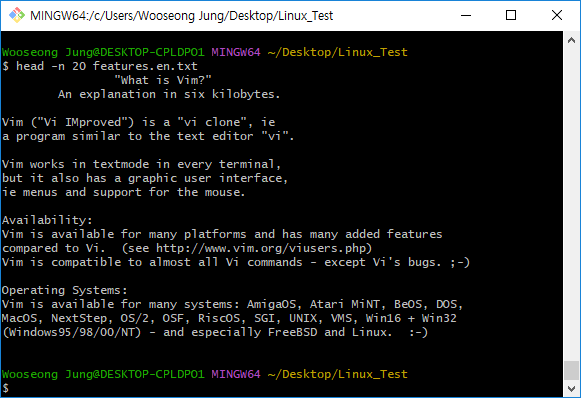
head -n [숫자] [파일명][확장자] // 처음부터 [숫자] 줄까지만 출력
tail [파일명][확장자]
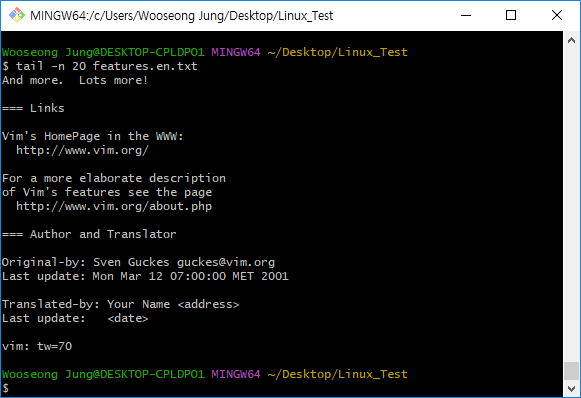
tail -n [숫자] [파일명][확장자] // 마지막부터 [숫자] 줄까지만 출력
// 예시
head -n 20 features.en.txt
tail -n 20 features.en.txt
📌 wc (word count, 텍스트 통계)
// 사용법
$ wc [파일명][확장자]
// 예시
$ wc features.en.txt
wc 명령어는 텍스트의 통계를 보여주는 명령어이다.
wc 명령어를 실행하면, 아래 사진처럼 총 3개의 숫자가 출력되고
각각 행(줄)의 갯수, 단어의 갯수, 바이트 수 를 의미한다.
참고 사항)
- 행의 갯수는 줄바꿈의 갯수를 나타내기 때문에 1이 적게 출력된다
- 영어는 한 글자 당 1 byte, 한글은 3 byte, 띄어쓰기는 1 byte, 줄바꿈은 2 byte

📌 nl(number lines, 행 번호 붙이기)
// 사용법
$ nl [파일명][확장자]
// 예시
$ nl features.en.txt
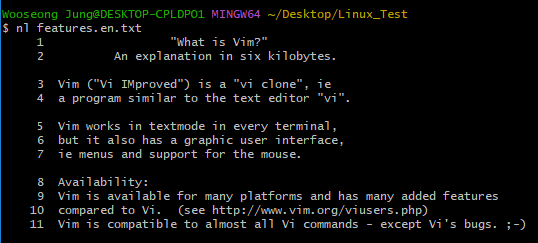
위 사진처럼 nl 명령어를 사용하면, 행 번호가 달린 상태로 출력된다.
📌 grep(Global Regular Expression Print, 파일 내용 검색)
// 사용법
$ grep "문자열" [파일명][확장자]
$ grep --collor "문자열" [파일명][확장자]
// 예시
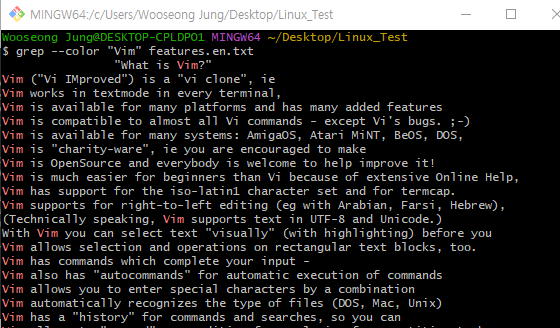
$ grep "Vim" feature.en.txt
$ grep --color "Vim" feature.en.txt
grep 명령어는 원하는 내용을 검색할 수 있도록 해주는 기능이며,
그냥 사용했을 때는 해당하는 문장만 찾아주기 때문에 어디에 단어가 위치하는지 찾기 힘들다.
따라서 --color 옵션을 사용하면, 아래 그림과 같이 하이라이트되어 더욱 찾기 쉬워진다.
📌 tr (translate, 문자 변환)
// 사용법
$ tr "문자1" "문자2" < [파일명][확장자]
// 예시
$ tr "Vim" "Vi IMproved" < features.en.txt
명령어 구조는 명령어 + OPcode + OPeRand로 구성되고
OPcode를 OPeRand로 "명령어"해라 라는 의미를 가진다.
이 개념을 적용시켜 보면,
문자1을 문자2로 변환해라 라는 의미가 되고
아까 배웠던 IO Redirection을 적용시키면,
파일의 문자1을 문자2로 변환시켜라 라는 뜻이 된다.
참고로 변환된 결과는 저장되지 않고 쉘에만 출력된다.
📌 sed (stream editorm, 텍스트 변환)
// 사용법
$ sed 's/문자열1/문자열2/g' [파일명][확장자]
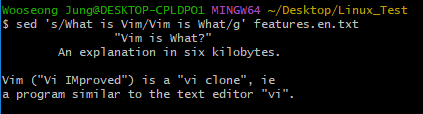
// 예시
$ sed 's/What is Vim/Vim is What/g' features.en.txt
문자를 변환하고 싶다면, tr
문자열을 변환하고 싶다면, sed 명령어를 사용해야 한다.
위 사용법처럼 's/문자열1/문자열2/g' 이 가장 기본적인 형태이며,
여기서 s는 substitute(텍스트 변환), g는 global이라는 뜻이고,
global은 해당 파일에 문자열1일 여러 번 나타나면 모두 변환시키라는 뜻이다.
✅ 파이프
흔히 파이프라는 용어는 어떤 두 물체나 공간을 연결시켜주는 개념으로 많이 사용하는데,
리눅스에서의 파이프는 한 번에 여러 개의 명령어를 사용할 수 있도록 하는 기능을 말한다.
리눅스 환경에서는 명령어의 결과가 파일에 저장되지 않는 경우가 대부분이기 때문에,
이전 명령어의 결과를 바로 받아서 다음 명령어에 사용하는 방법이 가능하다.
이 것을 정형화시킨 개념이 바로 파이프이고, 사용법은 다음과 같다.
// 사용법
$ 명령어1 | 명령어2 // 여기서 | 는 OR를 의미한다.
// 예시
// Vim을 Vi IMproved로 바꾸고,
// 가장 첫 20줄 중에서 Vi IMproved가 검색되는 행만 출력해주고
// Vi IMproved의 색을 바꿔서 출력해 줘.
$ sed 's/Vim/Vim IMproved/g' features.en.txt | head -n 20 | grep --color "Vi IMproved"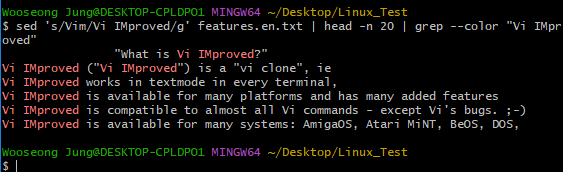
📌 sort (정렬하기)
// 사용법
$ sort [파일명][확장자]
// 예시
$ sort gang.txt
텍스트 파일을 하나 만들어 주자.
// Sort 예시 //
code - name - age
e3f8a602-b62e-4115-bbd6-0702cdb88afc Thomas 11
e794eda6-b5c6-4ea8-8f2a-7cb877d4d5d6 Michael 17
122edbb8-bcc0-46d8-8f0c-3fa7b54369e9 Robert 7
c10c3715-ee97-42e8-b906-6d50558378f4 Charles 7
27c50484-850d-4477-9893-1678b993c1b8 William 14
1a72c71-994f-4e2d-bfc0-26927aaa3164 John 9
9878141a-7dbb-42ce-a198-1a60b97a5fee Richard 16
1ac46560-3642-42bb-81af-ab0d882a7563 Joseph 11
23493703-dfa7-433f-abd3-dda0b8ded865 David 13
afa9061f-cc05-4470-bc28-e77b9a58b517 James 10
위와 같은 형태의 파일에서
이름, 나이, 키는 필드(변수)
각 인물에 대한 기록 한 줄 한 줄을 레코드라고 한다.
sort해보자.
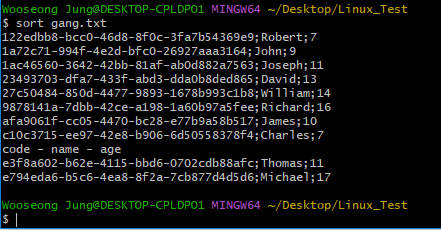
위와 같이 그냥 sort해버리면, 분류를 위해 작성한 code - name - age로 sort 돼버리므로
첫 줄은 제외하고 출력하도록 작성하야 한다.
위에서 배운 tail 명령어와 파이프를 활용해보자.
$ tail -n 10 gang.txt | sort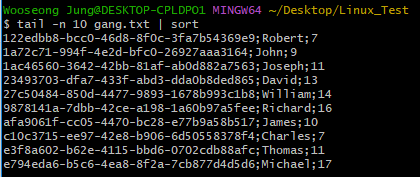
-k 옵션을 사용하여 다른 필드를 기준으로 sort해보자.
// 사용법
$ sort -k [숫자] [파일명][확장자]
// 예시
$ sort -k 2 gang.txt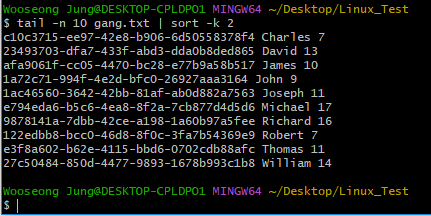
국가명과 같이 단어에 띄어쓰기가 포함된 문자의 경우, 필드 구분이 애매해질 수 있다.
이와 같은 혼동을 방지하기 위해, -t 옵션을 활용하여 필드 구분자를 지정해줄 수 있다.
code - name - age
e3f8a602-b62e-4115-bbd6-0702cdb88afc, Thomas, 11
e794eda6-b5c6-4ea8-8f2a-7cb877d4d5d6, Michael, 17
122edbb8-bcc0-46d8-8f0c-3fa7b54369e9, Robert, 7
c10c3715-ee97-42e8-b906-6d50558378f4, Charles, 7
27c50484-850d-4477-9893-1678b993c1b8, William, 14
1a72c71-994f-4e2d-bfc0-26927aaa3164, John, 9
9878141a-7dbb-42ce-a198-1a60b97a5fee, Richard, 16
1ac46560-3642-42bb-81af-ab0d882a7563, Joseph, 11
23493703-dfa7-433f-abd3-dda0b8ded865, David, 13
afa9061f-cc05-4470-bc28-e77b9a58b517, James, 10
// 일단 위와 같이 띄어쓰기 대신 ,로 작성한다.$ tail -n 10 gang.txt | sort -t", " -k 2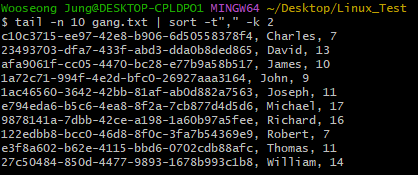
📌 uniq (중복 행 제거하기)
// 사용법
$ uniq [파일명][확장자]
// 예시
$ uniq gang.txt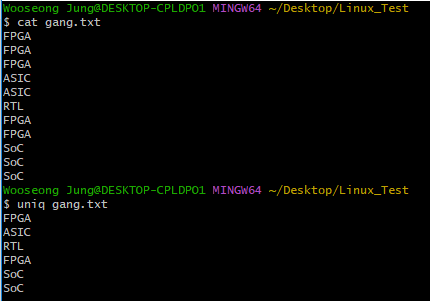
uniq 명령어는 텍스트에서 중복되는 행을 제거하여 하나의 행만 남도록 한다.
하지만, 건너 뛰어서 중복된 경우는 제거되지 않고,
연속적으로 중복되는 경우만 제거된다.
-c 옵션을 사용하면, 중복되는 것들의 갯수를 카운트할 수 있다.
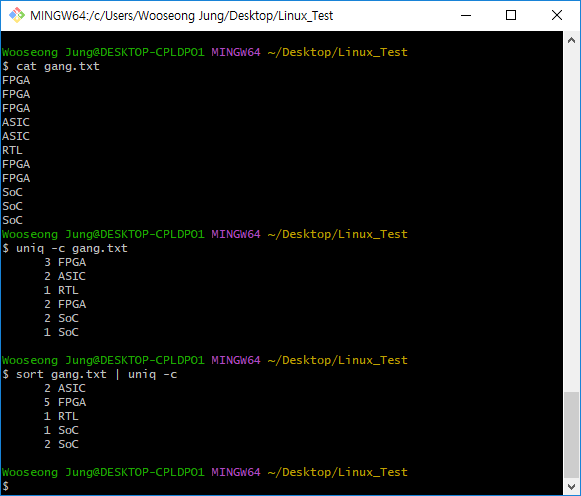
하지만, 연속적으로 중복되지 않는 것은 다른 문자로 취급하는 경우가 있으니,
항상 인접하도록 만들어준 다음에 uniq 명령어를 사용해야 한다.
참조 : 리눅스 기초 3장 by 문과생의 컴퓨터 연구소
'# Programming > - Linux 생태계 생존 가이드' 카테고리의 다른 글
| [Linux] 리눅스로 파일 압축하기(tar, gzip, unzip, 7z) - 리눅스 생태계 생존 가이드 Part.3 (1) | 2023.10.11 |
|---|---|
| [Linux] 기본 명령어 및 사용법 - 리눅스 생태계 생존 가이드 Part.2 (0) | 2023.10.05 |
| [Linux] 기본 개념 및 특징, 간단한 사용법 - 리눅스 생태계 생존 가이드 Part.1 (0) | 2023.09.19 |


