일단 이 것부터 알고 가자.
1. 포인터는 하나의 변수이다.
2. 포인터 변수 내에는 주소값만 들어갈 수 있다.
3. 배열은 같은 data type들의 모임
구조체는 서로 다른 data type들의 모임
4. 배열의 첫 번째 이름은 포인터처럼 행동한다.
[포인터]
주소값의 이해

- 데이터의 주소값
: 해당 데이터가 저장된 메모리의 시작 주소를 의미
int 형 데이터는 4byte의 크기를 가지지만,
각각의 데이터의 주소값은 시작 주소인 1byte만 가리킨다.
포인터란?
의미
: 메모리상에 위치한 특정한 데이터의 (시작)주소값을 보관하는 변수
= 포인터 변수 → 변수이기 때문에 값이 저장되는 공간을 가진다.
즉, 주소값만 가질 수 있는 변수
실제로 메모리에 접근할 수 있는 address는 각 1byte
int *ptr; // 4byte (32bit운영체제에서), 8byte(64bit운영체제에서)
→ int 형이므로 4byte
long *ptr1; // 4byte (32bit운영체제에서), 8byte(64bit운영체제에서)
→ data type이 다르지만, 크기가 같다
∵ 주소값만 가질 수 있기 때문에

포인터 선언 방법
: <data type *변수명;> 또는 <data type* 변수명;>
ex) int *ptr : 포인터가 가리키는 데이터의 data type이 int
포인터 연산자
1) 주소 연산자(&)
: 변수 이름 앞에 사용하며, 해당 변수의 주소값을 반환한다.
(= 번지 연산자)
▶ &a : a의 주소값
2) 참조 연산자(*)
: 포인터의 이름이나 주소 앞여 사용하며, 포인터가 가리키는 주소에 저장된 값을 반환
▶ *ptr : ptr이 쳐다보는 변수의 값
int main()
{
int *pi;
double *pd;
char *pc;
printf("pi의 포인터 크기 : %d\n", sizeof(pi));
printf("pd의 포인터 크기 : %d\n", sizeof(pd));
printf("pc의 포인터 크기 : %d\n", sizeof(pc));
// 64bit 운영체제이므로, 다 8byte로 출력됨
return 0;
}
포인터의 data type
포인터에 다양한 타입이 존재하는 이유
포인터 타입은 참조할 메모리의 크기 정보를 제공하는데,
타입별 크기가 각각 다르기 때문에 연산 시 증감하는 크기가 달라진다.
ex) char : 1byte씩 증감, int : 4byte씩 증감, double : 8byte씩 증감
포인터의 초기화
int*ptr;
ptr = 0x123456;
이처럼 초기화해도 컴파일 오류는 발생하지 않는다.
하지만, 잘못 초기화할 경우 심각한 문제가 발생할 수 있으니,
메모리 번지수가 할당된 것이 있고, 제조사에서 메모리 번지수를 알려줬을 경우에만 초기화할 것.
어떤 변수의 주소로 초기화할지 알 수 없다면, 0으로 초기화
int *ptr =0; // 가능
int *ptr1 = NULL; // 권장
int main()
{
int a;
a = 2;
printf("%p \n", &a); // 해당 변수의 주소값을 반환한다.
return 0;
}
위와 같이 메모리 주소는 실행될 때마다 할당되는 것이므로 변수의 이름만 가져가고, 주소값은 계속 바뀐다.
그러니, 따로 메모리 주소를 절대 할당하지 말 것.
연산자
1. 변수의 주소값을 알고 싶다면 & 사용
int main()
{
int *p; // 포인터 변수
int a; // 지역 변수
p = &a; // p가 a를 포인팅하게 함
printf("포인터 p에 들어있는 값 : %p\n", p); // 주소값이 들어 있으므로 %p
printf("int a가 저장된 주소 : %p\n", &a);
return 0;
}
2. 연산자 활용
int main()
{
int a, b; // 현재 상태는 쓰레기 값이 들어 있고
int *ptr; // 포인터 변수(ptr) 선언, 초기화되지 않은 상태
ptr = &a; // 포인터 변수(ptr)에 a의 주소값 넣어줌(a를 쳐다보는 상태)
*ptr = 2; // ptr이 쳐다보고 있는 곳에 2를 넣어줌
ptr = &b; // a를 쳐다보고 있다가 b를 쳐다봄
*ptr = 3; // 새로 쳐다보는 곳(b)에 3을 넣어줌
printf("a의 값 : %d \n", a);
printf("b의 값 : %d \n", b);
return 0;
}
다른 것은 다 잊어버려도 이 것만큼은 꼭 기억하자.
ptr = &a;
: ptr을 a의 주소값에 대입
= ptr이 a를 쳐다보게 해라.
*ptr = 3;
: ptr이 가리키는 주소(a)에 3을 대입
= ptr이 쳐다보는 변수에 3 대입
포인터의 덧셈
포인터도 변수라, 덧셈이 된다.(주소값을 증가시킨다는 의미)
단, 포인터끼리의 덧셈은 불가능하다.
∵ 포인터는 주소값이기때문에 덧셈불가
int main()
{
int a;
int *pa;
pa = &a;
printf(" pa의 값 : %p\n", pa);
printf("(pa+1)의 값 : %p\n", pa + 1); // data type 크기만큼 건너뛴다.
return 0;
} // ARM에서 비트 변형에 사용된다.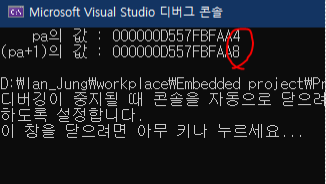
int main()
{
int arr[5] = { 1,2,3,4,5 };
int *parr = arr;
// int *parr;
// parr = &arr;
printf("%d\n", *parr); // 1
printf("%d\n", *(++parr)); // 2
printf("%d\n", *(++parr)); // 3
printf("%d\n", *(parr + 1)); // 4
printf("%d\n", *(parr + 2)); // 5
return 0;
} // 포인터는 변수이기 때문에 증감 연산이 가능하다.
// 배열은 상수로 취급되기 때문에 증감 연산 불가능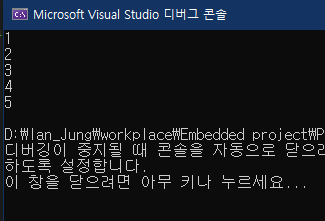
포인터와 배열을 통해 얻을 수 있는 결론
1차원 배열은 혼용이 가능하다
▶ arr[i] = *(arri + 1)
포인터의 대입
포인터끼리의 대입은 가능하다.
int main()
{
int a = 2;
int b = 3;
int *pa, *pb;
pa = &a; // pa는 a를 봐라
pb = &b; // pb는 b를 봐라
int *pc;
pc = pa; // pc는 pa가 보는 것을 봐라 -> a를 봐라
printf("pa의 값 : %d \n", *pa);
printf("pc의 값 : %d \n", *pc);
return 0;
}
함수와 포인터
기본적으로 값 혹은 주소를 스택 영역에 가져온 뒤, 사용한다.
함수를 사용하기 위해 argument를 전달하는 방식은
기본적으로 그 값을 복사하여 사용하고자 하는 함수의 매개변수에 전달하는 방식으로 이루어졌다.
(Call by value)
하지만 array같이 덩어리가 큰 argument들은 위와 같이 전달하기엔 문제가 발생하였고,
이를 해결하기 위해 배열 이름(배열 주소, 포인터)으로 argument를 전달한다.
(Call by reference)
Call by value vs Call by reference
Call by value : 값을 전달하는 방법
Call by reference : 주소값을 전달하는 방법
// Call by value //
int swap_value(int i); // 함수 원형 선언
int main()
{
int i = 0;
printf("호출 이전 i의 값 : %d\n", i);
swap_value(i);
printf("호출 이후 i의 값 : %d\n", i);
return 0;
}
int swap_value(int i)
{
i = 3;
return 0;
}
<call by value에 의한 swap>
int main()
{
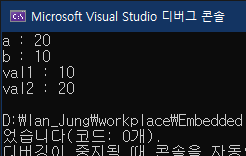
int val1 = 10;
int val2 = 20;
swap(val1, val2);
printf("val1 : %d\n", val1);
printf("val2 : %f\n", val2);
return 0;
}
void swap(int a, int b)
{
int temp = a;
a = b;
b = temp;
printf("a : %d\n", a);
printf("b : %d\n", b);
}
▶ val1의 값은 a에 복사되고 val2의 값은 b에 복사되어 전달하기 때문에,
val1과 val2 값이 바뀐 것이 아닌 a와 b의 값만 바뀌었다.
지역변수의 한계점
: 서로 다른 함수에서 서로의 지역변수에 접근 불가
(main 함수의 i ≠ swap_value 함수의 i)
// Call by reference //
int swap_value(int *ptr_i); // 포인터 변수로 넘겨줌
int main()
{
int i = 0;
printf("i변수의 주소값 : %p\n\n", &i);
printf("호출 이전의 i의 값 : %d\n\n", i);
swap_value(&i);
printf("호출 이후의 i의 값 : %d\n\n", i);
return 0;
}
int swap_value(int *ptr_i) // 주소값을 던졌기 때문에, 포인터 변수로 받아야 한다.(포인터 변수 선언)
{
printf("-------swap_value 함수 시작-------\n");
printf("ptr_i의 값 : %p \n", ptr_i);
printf("ptr_i가 가리키는 값 : %d\n", *ptr_i);
*ptr_i = 3; // ptr_i가 가리키는 값(i) 3으로 대체 --> i를 바꿈, ptr_i는 그대로
// ptr_i의 값은 변하지 않음
printf("-------swap_value 함수 끝-------\n\n");
return 0;
}
value 대신, 메모리 주소값을 저장하는 포인터 변수를 받아와 ptr_i가 가리키는 변수(i)를 바꾸는 함수가 되었다.
함수 포인터 & void 포인터
1. 함수포인터
포인터는 주소를 나타내며, 함수의 주소(위치)를 나타내기도 한다.
보통은 함수명과 매개 변수를 호출하는 방식을 많이 사용하는데,
이미 컴파일되어 있는 프로그램을 약간의 수정이 필요하여 외부에서 호출하는 경우에
함수의 포인터를 사용한다.
int fct1 (int a, int b)
{
int add = a+b;
return add;
}
int (*fptr) (int, int);
// 위 함수를 외부에서 호출
// 리턴type 함수포인터명 매개변수type;
2. void 포인터
void : 무형이라는 뜻
즉, function의 리턴값이 없을 때 그 type은 void
void 포인터는
① 자료형에 대한 정보가 제외된 주소 정보를 담을 수 있는 형태의 변수이다
② 포인터 연산, 메모리 참조와 관련된 일에 활용할 수 없다.
③ 메모리 추가 할당 시 사용한다.
프로그램 돌리다 메모리가 부족하면 malloc 함수로 메모리를 할당받아야 한다.
이때 void 포인터를 반드시 캐스팅(형변환 명령어)을 통해 필요한 데이터 타입으로
변환한 뒤 사용한다.
[배열]
배열이란?
의미
: 서로 같은 데이터형들의 유한 집합
둘 이상의 변수를 동시에 선언하는 효과를 가진다.
- element : 배열의 구성요소
- index : element들의 위치(차례)
0을 포함한 양의 정수만 가질 수 있다.
특징
- 배열은 연속된 메모리에 할당된다.
ex) 배열 10개 선언, 0~9번까지 연속되게 메모리를 할당받는다.
- 많은 양의 데이터를 일괄적으로 처리 가능
- 메인 함수에서 선언된 배열들은 stack 영역에 저장된다.
배열의 선언
data type 배열명 [배열의 갯수];
int arr[4]

: int type의 배열 4개를 연속해서 늘어 놓는다.
배열의 크기(갯수) 지정
[ ] 내부의 값을 달리하여 지정 가능
단, 배열 갯수에 변수를 사용할 수는 없다.
- const 사용해서 상수처리한 변수도 사용 불가능
- #define ARR_SIZE 5 처럼 매크로 상수를 선언한 경우는 사용 가능
ex) int arr[ARR_SIZE]
int main()
{
int arr[5]; // 크기가 5인(5개의 방을 가진) 배열 선언
int byte_size = 0; // 배열의 바이트 크기를 저장할 변수 선언
int size = 0; // 배열의 갯수를 저장할 변수
int i;
byte_size = sizeof(arr);
printf("배열의 바이트 크기 : %d\n\n", byte_size);
size = sizeof(arr) / sizeof(arr[0]); // 배열의 크기(원소의 갯수)
// 배열 전체 크기에서 배열 하나의 크기를 나누면 총 갯수가 나온다
printf("배열의 크기(갯수) : %d\n\n", size);
return 0;
}
배열의 초기화
배열의 초기화는
처음 선언할 때에 한해서 한 번에 모든 칸을 초기화 가능
int arr[10] = {0};
data type별 초기화
- int형은 0
- char형은 \0 (널문자)
- 실수형은 0.0
- bool형은 false
//배열의 초기화 //
int main()
{
int arr[5] = { 1,2,3,4,5 }; // 5개니까 element를 5개 넣는다.
// 각각의 element는 integer
printf("array 3번째 원소 : %d\n", arr[2]);
return 0;
}
int main()
{
int arr1[5] = {1, 2, 3, 4, 5};
int arr2[] = {1, 2, 3, 4, 5}; // 알아서 5개의 배열 생성
int arr3[5] = {1, 2} // 빈 칸은 0으로 채워줌
return 0;
}
element에 실수 대입
int main()
{
int arr[5];
arr[0] = 3;
arr[2] = 5;
arr[3] = 4.5;
printf("array 3번째 원소 : %d\n", arr[2]);
printf("array 3번째 원소 : %d\n", arr[3]); // 반올림 안 하고 버림해버린다.
return 0;
}
[] 에 변수 대입
int main()
{
int arr[10];
int i = 5; // 변수 못 쓴다고 했는데, 왜 결과가 나옴?
// 처음 선언할 때만 못 쓰고 몇 번째에 뭘 넣어줄 지 정하는 건 가능
arr[i] = 3;
arr[i + 1] = 5;
arr[i + 3] = 7;
printf("array 6번째 원소 : %d\n", arr[i]);
printf("array 7번째 원소 : %d\n", arr[i+1]);
printf("array 9번째 원소 : %d\n", arr[i+3]);
return 0;
}
#define ARR_SIZE 5
int add(int a, int b) { return a + b; } // 함수 원형 선언하는 척 함수 만들어 버림
int main()
{
int arr[ARR_SIZE] = {0}; // 0으로 초기화 : 배열 5개를 전체 다 0으로 초기화
// int arr[5] = {0, 1, 3} 이렇게 치면, 0 1 3 0 0 이렇게 초기화됨.
// (초기화 안 해준 부분은 0으로 자동 초기화)
int i;
arr[0] = 5;
arr[1] = arr[0] + 10;
arr[2] = add(arr[0], arr[1]);
printf("정수를 2개 입력하세요 : \n");
scanf("%d %d", &arr[3], &arr[4]);
for (i = 0; i < ARR_SIZE ; i++) // 반복문 활용, 배열 내용을 하나씩 출력
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}




문자열
문자열 = 문자들의 배열 + null
하나 하나는 단일 문자, 이들의 배열이 문자열
'A' : 단일 문자 A
"A" : 문자열 A
문자열 변수
문자열이면서 변수의 특징을 가진다.
ex) char = str1[5] = "Good";
문자는 총 4개인데, 왜 5개의 방을 가지는가?
∵ 문자열의 마지막에는 null(\0)가 포함되기 때문이다.
□ □ □ □ □
G o o d \0
위와 같이 마지막에 null이 들어간다.

null 문자를 지녀야 하는 이유
- 문자열의 끝을 표현하기 위해서
- 쓰레기 값과 실제 문자열의 경계를 나타내기 위해
- printf 함수는 널문자를 통해서 출력의 범위를 결정짓는다.
문자열과 char 형 배열(문자 배열)의 차이점
- 문자 배열 : 말 그대로 문자들만 모여서 배열을 만든 것
char arr2[] = {'a', 'b', 'c'};
// → a b c
// → 각각의 문자들은 사실 정수값(ASCII Code 참조)
// 따지고 보면, 문자열이 아니다
char arr1[] = "abc";
// → a b c \0
// = char arr[] = {'a', 'b', 'c', '\0'};위와 같은 혼동 요인은 가급적 배제해라.
문자열 표현 방식의 이해

- 배열 기반의 문자열 변수
char str1[5] = "abcd";
- 포인터 기반의 문자열 상수(char *)
char *str2 = "ABCD"
→ 상수 영역에 저장되며, 변경할 수 없다.
→ str2가 쳐다보는 곳에 ABCD를 대입해라
int main()
{
char str1 [5] = "abcd";
char *str2 = "ABCD";
printf("%s \n", str1);
printf("%s \n", str2);
str1[0] = 'x';
// str2[0] = 'x' ---> ERROR
// 상수형이므로 대입이 불가능하다
printf("%s \n", str1);
printf("%s \n", str2);
return 0;
}
int main()
{
char *str1 = "ABCD";
char *fm = "%s\n";
printf(fm, str1);
printf("%s\n", str1);
// 둘 다 같은 결과를 출력한다.
return 0;
}
배열의 복사
각각의 요소에 대해 1:1로 대응시켜줘야 복사가 된다.
// 배열의 복사 //
int main()
{
int x[5] = { 1,2,3,4,5 };
int y[5] = { 0 };
y = x; // 이렇게 쓰면 오류난다.
}
int main()
{
int x[5] = { 1,2,3,4,5 };
int y[5] = { 0 };
for (int i = 0; i < 5; i++)
{
y[i] = x[i];
} // 각각의 요소에 대해 1:1로 대응시켜줘야 복사가 된다.
}
배열의 메모리
- 각 변수들은 모두 메모리에서 자신의 크기만큼의 메모리를 점유하고 있다.
- 4byte 크기의 변수인 int는 4byte
- char 변수는 1byte
int main() // 일반 변수의 주소값(임의대로 바뀐다.)
{
int i = 5;
char c = 'A';
printf("변수 i의 주소값 : %p\t 변수 i의 값 : %d\n", &i, i);
printf("변수 c의 주소값 : %p\t 변수 c의 값 : %d\n", &c, c);
return 0;
}
// 배열의 메모리 //
int main()
{
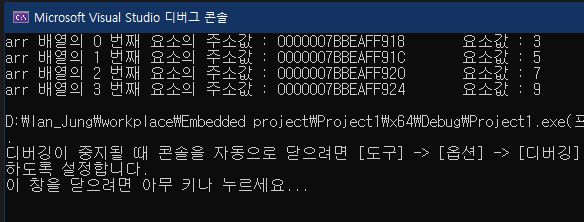
int arr[4] = { 3,5,7,9 };
// int arr[] = { 3,5,7,9 }; 이렇게 값을 비워주면 알아서 지정된다.
for (int i = 0; i < 4; i++) // 변수 i의 선언을 for 문 안에서 할 수 있다.
{
printf("arr 배열의 %d 번째 요소의 주소값 : %p\t 요소값 : %d\n", i+1, &arr[i], arr[i]);
}
return 0;
}
2차원 배열
2D array 라고도 부른다.
// 2차원 배열의 선언 //
int main()
{
int arr_2[3][3] = {{1,2,3}, {4,5,6}, {7,8,9}};
int arr_2_1[3][3] = { 1,2,3,4,5,6,7,8,9 }; // 숫자만 맞으면, 지가 알아서 끊는다
int arr_2_2[3][3] = { 0 }; // 전체 0으로 초기화
return 0;
}
<예시>
int main() // 2차원 배열 예시
{
int arr2[3][3] = {
{1,4,6},
{8,5,2},
{7,9,3}
};
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
printf("%d행 %d열 : %d", i, j, arr2[i][j]);
if (j < 3) printf(" | ");
if (j == 2) printf("\n");
}
}
return 0;
}
<예시2>
int main()
{
int arr2[][3] = { /// 행은 비워도 동작함, 열은 비우면 안 된다.
{1,4,6},
{8,5},
{7,9,3}
};
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
printf("%d행 %d열 : %d | 주소 %p \n", i, j, arr2[i][j], &arr2[i][j]);
}
}
return 0;
}
[배열과 포인터]

// 배열을 포인터로 접근해보자
int main()
{
int arr[5] = { 1,2,3,4,5 };
int *parr; // 배열의 포인터 선언
// *parr 대신, parr[] 로 받을 수도 있다.
int i;
parr = &arr[0]; // 주소를 넣어준다. 항상 내가 가리키는 것의 첫 번째 것을 넣어준다.
// parr이 배열의 첫 번째를 쳐다보게 해라.
// arr의 첫 번째 element(arr[0])의 주소가 parr
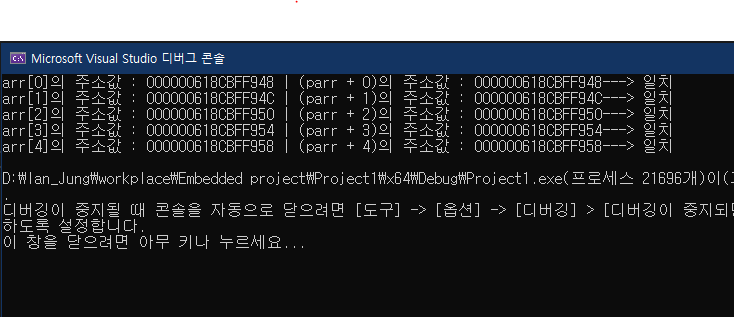
for ( i = 0; i < 5; i++)
{
printf("arr[%d]의 주소값 : %p | ", i, &arr[i]);
printf("(parr + %d)의 주소값 : %p", i, (parr+i));
// parr+1 : 4byte씩 뛰어 넘는다. 각 배열을 하나씩 건너뛴다 생각하면 됨.
if (&arr[i] == (parr + i))
{
printf("---> 일치 \n");
}
else
{
printf("---> 불일치 \n");
}
}
return 0;
}
parr++
: "다음 방으로 넘어간다" 생각하면 편하다.
arr[0]-> arr[1] -> arr[2] -> arr[3] 이렇게 다음 방으로 건너 뛴다
① 주소값에 왜 4가 추가됨?
: int 형 구조에서 방 하나의 포인터 변수 크기는 4byte 이므로
② *parr = *(parr+0) = arr[0]
*(parr+1) = arr[1]
→ 다음 방으로 넘어감
*parr + 1 = arr[0] + 1
→ 방의 값에 1을 더함
int main()
{
int arr[5] = { 1,2,3,4,5 };
int *parr; // 배열의 포인터 선언
int i;
parr = &arr[0];
printf("arr[3] = %d \n *(parr + 3) = %d \n", arr[3], *(parr + 3));
// arr[0]의 주소에 3을 더하니, arr[3]이 된다.
return 0;
}
배열의 첫 번째는 배열의 포인터처럼 행동한다.
int *parr;
parr = &arr일 때,
*parr 은 arr[0] 과 같다.(물론 데이터 크기는 다름)
∵ 포인터 처럼 행동하기 때문

또한 배열은 상수이므로 증감 연산(arr++)이 불가능하다.
포인터는 변수이므로 증감 연산(ptr++)이 가능
여기서 얻을 수 있는 결론
1차원 배열은 혼용이 가능하다!
arr[i] = *(arr+i)
int main()
{
int arr[5] = { 1,2,3,4,5 };
printf("arr의 정체 : %p \n", arr);
printf("arr[0]의 주소값 : %p \n", &arr[0]);
// 배열의 첫 번째 arr가 포인터처럼 행동한다는 의미.
// 배열 = 포인터 가 된다는 의미가 아님
return 0;
}

int main()
{
int arr[5] = { 1,2,3,4,5 };
int *parr = arr; //&arr[0]
printf("sizeof(arr) : %d\n", sizeof(arr));
printf("sizeof(parr) : %d\n", sizeof(parr));
// 똑같은 줄 알았는데, 사이즈가 다르다.
// 포인터 처럼 행동을 한다는 것이지, 포인터가 되는 것이 아니다.
return 0;
}
int main()
{
int arr[3] = { 1,2,3 };
int *parr;
parr = arr; // 아무 문제없다. 포인터처럼 행동하니까!
printf("arr[1] : %d\n", arr[1]);
printf("parr[1] : %d \n", parr[1]);
return 0;
}
중첩포인터

// 중첩 포인터 //
int main()
{
int a;
int *pa;
int *ppa;
pa = &a; // pa는 a를 바라보게
ppa = &pa; // ppa는 pa를 바라보게
// 따라서 ppa가 a를 바라봄 --> 이중 포인터라고도 한다.
return 0;
}
int main()
{
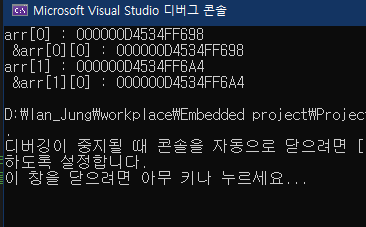
int arr[2][3]; // value 값을 보려는 것이 아닌, 주소값을 보기 위해서
printf("arr[0] : %p\n", arr[0]);
printf(" &arr[0][0] : %p\n", &arr[0][0]);
// arr[0]은 arr[0][0] 을 가리키는 암묵적 포인터 역할을 한다.
// 각 행의 대장이 포인터 역할을 한다.
// (순간적으로 포인터 역할만 한다. 사이즈는 포인터와 다름)
printf("arr[1] : %p\n", arr[1]);
printf(" &arr[1][0] : %p\n", &arr[1][0]);
return 0;
}
2차원 배열의 갯수 계산
int main()
{
int arr[2][3] = {
{1,2,3},
{4,5,6}
};
printf("전체 크기 : %d\n", sizeof(arr));
printf("총 열의 갯수 : %d\n", sizeof(arr[0]) / sizeof(arr[0][0]));
// 12byte / 4byte = 3개
printf("총 행의 갯수 : %d\n", sizeof(arr) / sizeof(arr[0]));
// 24byte / 12byte = 2개
return 0;
}
2차원 배열과 포인터
2차원 배열 이후부터는
가급적이면 포인터 형태로 argument를 주고받지 않는 것이 정신 건강에 좋다.
정확하게 이해하지 않는다면, 사용하기에 너무 복잡하다
솔직히 정확히 이해해도 해석에 오해 소지가 있기에, 웬만하면 지양하도록 하자.

1차원 배열은
*(parr+0), *(parr+1)로 해당 배열에 acess할 수 있다.
즉, 배열의 0번째 방이 그 배열의 포인터 역할을 한다는 것을 알 수 있다.
∴ *((ptr+2)+n)
→ 2차원 배열 arr [ ] [ ] 의 2행 n열을 가리키는 포인터
위와 같이 포인터의 포인터 형태로 2차원 배열의 포인터 선언을 할 수 있다.
cf) C언어는 Zero base(0부터 시작)인 것을 기억할 것
가급적 쓰지 말랬는데, 왜 있음?
문자열의 배열에 사용됨.
ex) 이름의 배열
이름은 이미 문자이기 때문에, 2차원 배열로 작성된다.
<포인터 배열 vs 배열 포인터>
1. 포인터 배열

배열 요소 자체가 포인터
문자열 배열이 위와 같은 타입으로 구성되며, 각각의 요소들은 문자열 배열
포인터 배열을 주로 사용한다.
2. 배열 포인터

배열 자체를 포인터로 가리킨다.
총 몇 개가 될 지 모름, 어쨌거나 포인터
다행히 잘 사용 안 한다.
int main()
{
int arr[3][2] = {
{1, 2},
{3, 4},
{5, 6}
};
printf(" arr[0] : %d\n", arr[0]);
printf(" *(arr+0) : %d\n\n", *(arr + 0));
printf(" arr[1] : %d\n", arr[1]);
printf(" *(arr + 1) : %d\n\n", *(arr + 1));
printf(" arr[2] : %d\n", arr[2]);
printf(" *(arr + 2) : %d\n\n", *(arr + 2));
printf(" %d, %d \n", arr[1][0], (*(arr + 1))[0]);
printf(" %d, %d \n", arr[1][2], *(arr[1]+2));
printf(" %d, %d \n", arr[2][1], *(*(arr+2)+1));
return 0;
}
<문자열의 배열>
char *arr [3] = {"abcd", "aacc", "eeee"};
바이트 저장 순서
1. Big-endian(BE)

빅 엔디안 방식은 낮은 주소에 데이터의 높은 바이트(MSB : Most Significant Byte)부터 저장하는 방식이다.
이 방식은 평소 사람이 사용하는 선형 방식과 같아 메모리에 저장된 순서 그대로 읽을 수 있으며, 이해하기 쉽다.
2. Little-endian(LE)

리틀 엔디안 방식은 낮은 주소에 데이터의 낮은 바이트(LSB : Least Significant Byte)를 저장하는 방식이다. 이 방식은 평소 사람이 숫자를 사용하는 선형 방식과 반대로 거꾸로 읽어야 한다.
[구조체]

의미
: 서로 다른 data type의 변수들을 하나로 묶어서 사용하는 기능을 가지며
사용자 정의형을 만드는 방법을 제공한다.
- Member : 구조체 각각의 구성요소
- Data type : struct contact type
특징
- 구조체가 선언된 순서대로 메모리 할당이 이루어진다
- 관련있는 서로 다른 자료형을 한덩어리(집합)로 만들어 처리 가능
- 네트워크 프로그램을 작성할 때, 소켓이나 헤더(header)의 format(형식)을 구조체로 묶어서 처리
- 함수를 반환할 때 한 개의 데이터가 아닌 구조체단위로 묶어서 전달 가능
구조체와 배열 비교

- 구조체 : 서로 다른 타입들의 모임
- 배열 : 서로 같은 타입들의 모임
구조체 변수의 선언
구조체 변수가 메모리에 할당될 때,
구조체의 멤버들이 선언된 순서대로 메모리에 할당된다.
struct human { // human이라는 구조체 정의
int age;
int height;
int weight;
};
// }human_info; // 이렇게 구조체와 변수를 함께 선언해도 된다.
// 이렇게 선언하면 메인 함수에서는 선언x
int main() {
struct human info; // info라는 변수를 구조체 데이터형으로 선언
int i = 0;
info.age = 99; // 멤버 변수에 접근 : 변수명.멤버명
info.height = 183;
info.weight = 81;
printf("info 에 대한 정보 \n");
printf("나이 : %d \n", info.age);
printf("키 : %d \n", info.height);
printf("몸무게 : %d \n", info.weight);
return 0;
<구조체 여러 개를 동시에 선언>
struct test{
int a;
int b;
} st1, st2, st3;
int main()
{
...........
}
// 또는
struct test{
int a;
int b;
}
int main()
{
struct test st1, st2, st3;
..........
}
// 이렇게 같은 형태의 구조체를 여러 개 선언할 수도 있음.
변수의 초기화
배열의 초기화와 비슷하게 하면 된다.
{ } 안에 멤버들의 초기값을 멤버가 선언된 순서대로 나열
struct contact ct = { "김석진", "01012345678",0 };
// ct.name ct.phone ct.ringtone
초기값이 멤버의 개수보다 부족하면 나머지 멤버들은 0으로 초기화
struct contact ct = { "김석진", "01012345678" };
// ringtone은 0으로 초기화
멤버의 갯수보다 초기값이 더 많다면, 컴파일 에러 발생
struct contact ct = { "김석진", "01012345678", 0, 1 };
// 컴파일 에러
초기값이 {0}을 지정하면 모든 멤버가 0으로 초기화
struct contact ct = { 0 }; // 모든 멤버가 0으로 초기화
구조체 변수의 사용
구조체의 멤버에 접근하려면 멤버 접근 연산자 (.)를 이용
구조체 변수를 여러개 선언하면, 각각의 구조체 변수는 서로 다른 메모리에 할당됨
strcpy
: string copy라는 명령어
- 사용법 : strcpy(destination, source)
- #incluce <string.h> 이렇게 헤더파일 하나를 추가해줘야 사용 가능.
#include <string.h>
struct contact { // 연락처 구조체
char name[20]; // 이름
char phone[20]; // 전화번호
int ringtone; // 벨소리 (0~9) 선택
};
int main() {
struct contact ct = { "김석진", "01012345678", 0 };
struct contact ct1 = { 0 }, ct2 = { 0 }; // 멤버를 0으로 초기화
ct.ringtone = 5; // ct에서 ringtone을 0으로 바꿈
strcpy(ct.phone, "01000008765"); // ct에서 phone를 바꿈
printf("이 름 : %s \n", ct.name);
printf("전화번호 : %s \n", ct.phone);
printf("벨 소 리 : %d \n", ct.ringtone);
strcpy(ct1.name, "전정국"); // 별도의 구조체 ct1 의 name를 대입
strcpy(ct1.phone, "01188889999"); // ct1 에 phone 대입
ct1.ringtone = 1; // ct1 에 ringtone 대입
printf("이 름 : %s \n", ct1.name);
printf("전화번호 : %s \n", ct1.phone);
printf("벨 소 리 : %d \n", ct1.ringtone);
// 연락처를 받아본다
printf("이 름 : ");
scanf("%s", ct2.name); // 배열명으로 받음
printf("전화번호 : ");
scanf("%s", ct2.phone); // 배열명으로 받음
printf("벨소리(0~9) : ");
scanf("%d", &ct2.ringtone); // 주소 연산자 조심
printf("이 름 : %s \n", ct2.name);
printf("전화번호 : %s \n", ct2.phone);
printf("벨 소 리 : %d \n", ct2.ringtone);
return 0;
}
구조체 변수간의 초기화
구조체 변수를 다른 구조체 변수로 초기화하면,
동일한 멤버간 1:1 대응해서 초기화 한다.
struct contact ct2 = ct1;
// 구조체 변수를 다른 구조체 변수로 초기화
{} 안에 나열된 값을 서로 대입할 수 없다.
ct2 = { "김석진", 01022224444 };
// {}는 초기화할 때만 사용가능하므로 컴파일 에러
구조체의 멤버인 배열끼리의 대입 → 컴파일 에러 발생
ct2.name = ct1.name;
// 배열에 다른 배열을 대입하면 컴파일 에러
구조체 변수의 비교
구조체 변수끼리 직접 관계 연산자로 비교 불가하다.
if (ct1 == ct2)
// 구조체 변수에 관계연산자 사용 불가
// 컴파일 에러발생
두 구조체 변수의 값이 같은지 비교하려면,
멤버 : 멤버로 비교해야 한다.(구조체 통으로 비교x)
strcmp : string compare 명령어
if (strcmp(ct1.name, ct2.name) == 0 && strcmp(ct1.phone, ct2.phone) == 0
&& ct1.ringtone == ct2.ringtone);
printf("ct1 과 ct2의 값이 같습니다 \n");
typedef
기존 데이터형에 대한 별명(Alias)
typedef는 Type Define의 약자로, data type을 재 정의하라는 의미.
ex) typedef int Modesty;
int a → Modesty a 로 써도 결과는 동일하다.
보통 int형을 INT32, INT16 과 같이 가독성 좋게 바꾸는데 사용한다.
// typedef 사용법 //
typedef unsigned int UINT; // 자료형 재정의
// unsigned int -> UINT
int main() {
UINT num; // 재정의된 자료형 이름
num = 10;
printf("Num : %d \n", num);
return 0;
}
<구조체에서의 typedef>
typedef struct food
{
char name[10];
int iPrice;
int iCookTime;
int iPreference;
}FOOD; // 구조체 변수가 아닌 재정의 한 형식의 이름
// struct food -> FOOD
int main() {
FOOD Food = { "라면", 3500, 3, 5 };
printf("음식 이름 : %s \n", Food.name);
printf("음식 가격 : %d \n", Food.iPrice);
printf("조리 시간 : %d \n", Food.iCookTime);
printf("음식 평가 : %d \n", Food.iPreference);
return 0;
}
// 구조체 형식을 재 정의 했기 때문에 FOOD 나 food 로는 접근 불가
구조체와 배열
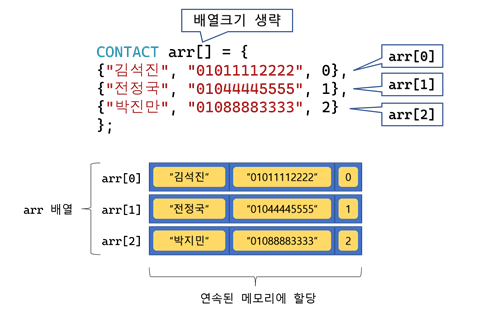
- 같은 구조체형의 변수를 여러 개 묶어서 사용하는 방식
- 구조체 멤버에 접근하려면, arr[i].member 형식으로 접근
typedef struct contact
{
char name[20];
char phone[20];
int ringtone;
}CONTACT;
int main() {
CONTACT arr[] = { // 구조체를 배열로 선언(배열 초기화)
{"김석진", "01011112222", 0},
{"전정국", "01044445555", 1},
{"박진만", "01088883333", 2}
};
int size = sizeof(arr) / sizeof(arr[0]); // 배열 내 구조체의 갯수
int i;
printf(" 이름 전화번호 벨소리 \n");
for (i = 0; i < size; i++)
{
printf("%6s %15s %5d\n", arr[i].name, arr[i].phone, arr[i].ringtone);
}
return 0;
}
구조체와 포인터
구조체 변수의 주소를 저장하는 포인터
이 것만 알면, 이해하기 편하다. 포인터 별 거 없잖아
1) p = &a
: p는 a를 쳐다봐라
2) *p = 2
: p가 쳐다보는 변수(a)에 2를 대입해라
struct test {
int a, b;
};
int main() {
struct test st;
struct test *ptr; // struct test 형을 가리키는 포인터 변수 선언
// 절대 구조체가 아니고 포인터 변수임 (8바이트)
ptr = &st; // ptr 에 st 주소값을 넣음
// ptr은 st를 쳐다봐라.
(*ptr).a = 1; // ptr.a 가 쳐다보는 구조체 변수 st.a에 1을 넣어라
(*ptr).b = 2; // 연산자 우선 순위 때문에 반드시 괄호를 해줘야 함
printf("st 의 a 멤버 : %d \n", st.a);
printf("st 의 b 멤버 : %d \n", st.b);
return 0;
}
간접연산자 ->
// 위와 같은 결과 출력됨 //
struct test {
int a, b;
};
int main() {
struct test st; // 구조체 변수 선언
struct test *ptr; // 구조체의 포인터 변수 선언
ptr = &st; // 구조체도 배열의 일종이지만 배열 이름으로는 주소값 못 받음
ptr->a = 1; // (*ptr).a 를 -> 를 사용하여 바꿈
// st를 쳐다 봐! -> a=1을 넣어!
ptr->b = 2; // 간접연산자 -> 사용 (구조체 포인터 접근시 사용)
printf("st 의 a 멤버 : %d \n", st.a);
printf("st 의 b 멤버 : %d \n", st.b);
return 0;
}
------------------------------
구조체와 배열 & 포인터 활용
실제 변수와 포인터변수의 멤버 접근법
- 실제 변수
: 접근 연산자(.) 을 사용하여 접근
- 포인터 변수
: 간접 연산자(->) 을 사용하여 접근
struct person {
char name[20];
char phone[20];
};
int main()
{
struct person man={"Thomas", "354-00xx"};
struct person * pMan;
pMan=&man; // pMan은 구조체 man을 쳐다 봐라.
// 구조체 변수를 이용한 출력.
printf("name : %s\n", man.name);
printf("phone : %s\n", man.phone);
// 구조체 포인터를 이용한 출력1.
printf("name : %s\n", (*pMan).name);
printf("phone : %s\n", (*pMan).phone);
// 구조체 포인터를 이용한 출력2.
printf("name : %s\n", pMan->name);
printf("phone : %s\n", pMan->phone);
return 0;
}
함수 인자로 전달되는 구조체 변수
구조체 변수의 argument(인자) 전달 방식은 기본 자료형 변수의 인자 전달 방식과 동일하다.
(Call by value = 실제 변수 그대로 전달)
→ 복사한 뒤 다 stack 영역에 때려 박은 다음에 전달
구조체의 데이터 크기가 크지 않다면 call by value 방식으로 전달해도 문제가 없다.
하지만, 실제로 실무에서 사용하는 구조체의 대부분은 구조도 복잡하고 크기도 상당히 크다(char array 등)
이렇게 데이터 크기가 큰 구조체를 call by value 방식으로 전달하면 순간적으로 stack에 막대한 데이터가 쌓이게 되
이는 stack overflow를 일으킬 수 있다.
∴ 포인터로 전달(call by reference)하는 것을 권장한다.
공용체(UNION)

이름만 다를뿐, 구조는 struct와 똑같다.
차이점 : 내부에서 메모리 공간을 차지하는 형태
구조체 : 데이터가 많으면 많을수록 더 많은 메모리 공간이 필요함
공용체 : 하나의 메모리 공간을 둘 이상의 변수가 공유
서로 다른 타입일지라도, 메모리 공간은 동일하게 사용
공용체의 활용
통신을 위해서는 데이터를 주고받아야 한다.
데이터는 패킷 단위로 묶어서 보내게 되는데, 단순히 보내는 건 쉽지만 받는 입장에서는 덩어리로 온 데이터를 받아서 분해하고 다시 묶어서 보내기가 여간 까다롭다. 정확히는 까다롭다기보다는 귀찮다. 그런데 위와 같이 공용체를 사용한다면 보낼 때는 buffer로 한 번에 보내고 받을 때는 struct의 변수들로 각각 받을 수 있어서 편리하다.
즉, 멤버간의 메모리를 공유하여 사이즈를 적게 설계할 수 있으며, 바이트 단위로 통신하므로 비트 단위로 통신하는 구조체보다 더 빠르고 수월하게 데이터를 주고 받을 수 있다.
이 것만 알고 가도 충분함.
1. 포인터는 하나의 변수이다.
2. 포인터 변수 내에는 주소값만 들어갈 수 있다.
3. p = &a : p는 a를 쳐다봐라.
*p = 1 : p가 쳐다보는 변수(a)에 1을 넣어라.
4. 배열은 같은 data type들의 모임
구조체는 서로 다른 data type들의 모임
5. 배열의 첫 번째 이름은 포인터처럼 행동한다.
'# Semiconductor > [Semicon Academy]' 카테고리의 다른 글
| [Harman 세미콘 아카데미] 15일차 - C언어(함수~구조체 및 표준함수) (0) | 2023.07.07 |
|---|---|
| [Harman 세미콘 아카데미] 14일차 - 강의 일정 Summary(ARM Architecture 이해 및 RTOS 활용), C언어 review (0) | 2023.07.06 |
| [Harman 세미콘 아카데미] 13일차 - C언어 문법(조건문, 반복문, 함수) (0) | 2023.07.05 |
| [Harman 세미콘 아카데미] 12일차 - Review, 디지털 시계 만들기(교육 과정 외) (0) | 2023.07.04 |
| [Harman 세미콘 아카데미] 11일차 - 반도체 개요, C언어 개요 및 문법 (0) | 2023.07.03 |



